import plotly.express as px
import pandas as pd
import seaborn as sns
from datetime import timedelta, date, datetime
import plotly.io as pio
pio.renderers.default='notebook'4 Curvas epidémicas
Ahora que ya tenemos idea de cómo procesar los datos y conocemos más o menos su contenido, podemos empezar a hacer algunas visualizaciones. En general, el flujo de análisis de datos va y viene entre el preproceso, la visualización y el análisis. El tipo de preproceso va ligado a las visualizaciones que queremos hacer y estas van mostrando el camino del análisis, por lo tanto en la vida real uno siempre está yendo y viniendo entre estas etapas.
En este taller vamos a explorar gráficamente los datos y empezarnos a hacer preguntas sobre ellos, preguntas que intentaremos ir respondiendo con nuevas visualizaciones. Para ello vamos a partir de la base de datos que construimos en el taller anterior.
Como siempre, lo primero es importar las librerías que vamos a utlizar
Vamos a utilizar los datos preprocesados que guardamos al final del taller anterior. Recordemos que los guardamos como csv, entonces los datos van a incluir el proceso que implique cambiar valores, pero no van a recordar los tipos de datos que cambiamos, entonces, despues de leer los datos, vamos a ajustar los tipos de las columnas de fecha.
df = pd.read_csv("datos/covid_enero_2023_procesados.csv", index_col=0)
df['FECHA_INGRESO'] = pd.to_datetime(df['FECHA_INGRESO'], format="%Y-%m-%d")
df['FECHA_SINTOMAS'] = pd.to_datetime(df['FECHA_SINTOMAS'], format="%Y-%m-%d")
df['FECHA_DEF'] = pd.to_datetime(df['FECHA_DEF'], format="%Y-%m-%d", errors='coerce')
df/tmp/ipykernel_89594/2932843985.py:1: DtypeWarning:
Columns (13) have mixed types. Specify dtype option on import or set low_memory=False.
| FECHA_ACTUALIZACION | ID_REGISTRO | ORIGEN | SECTOR | ENTIDAD_UM | SEXO | ENTIDAD_NAC | ENTIDAD_RES | MUNICIPIO_RES | TIPO_PACIENTE | ... | CARDIOVASCULAR_BIN | OBESIDAD_BIN | RENAL_CRONICA_BIN | TABAQUISMO_BIN | OTRO_CASO_BIN | TOMA_MUESTRA_LAB_BIN | TOMA_MUESTRA_ANTIGENO_BIN | MIGRANTE_BIN | UCI_BIN | DEFUNCION | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2023-01-03 | 180725 | 2 | 9 | CIUDAD DE MÉXICO | 2 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | TLALPAN | HOSPITALIZADO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 4 | 2023-01-03 | 1933c0 | 1 | 12 | CIUDAD DE MÉXICO | 2 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | IZTAPALAPA | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 8 | 2023-01-03 | 0741e4 | 2 | 6 | CIUDAD DE MÉXICO | 2 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | MIGUEL HIDALGO | HOSPITALIZADO | ... | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 13 | 2023-01-03 | 1c4d2e | 2 | 9 | CIUDAD DE MÉXICO | 1 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | TLALPAN | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 15 | 2023-01-03 | 0a6cd6 | 2 | 6 | CIUDAD DE MÉXICO | 1 | NAYARIT | CIUDAD DE MÉXICO | IZTAPALAPA | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6393642 | 2023-01-03 | m1cd235 | 2 | 12 | MÉXICO | 1 | MÉXICO | CIUDAD DE MÉXICO | GUSTAVO A. MADERO | HOSPITALIZADO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6394417 | 2023-01-03 | m0dbc4c | 2 | 12 | MÉXICO | 1 | AGUASCALIENTES | CIUDAD DE MÉXICO | AZCAPOTZALCO | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6394626 | 2023-01-03 | m13431e | 2 | 12 | MÉXICO | 1 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | AZCAPOTZALCO | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 6394988 | 2023-01-03 | m1493ea | 2 | 12 | MÉXICO | 1 | MÉXICO | CIUDAD DE MÉXICO | GUSTAVO A. MADERO | AMBULATORIO | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6395781 | 2023-01-03 | m0a22b8 | 2 | 12 | MÉXICO | 2 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | TLALPAN | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1896084 rows × 63 columns
Note
El parámetro index_col=0 le dice al lector que la primera columna (que no tiene nombre en el csv) es el índice de los datos.
4.1 Curvas epidémicas
Lo primero que haremos será el desarrollo de Curvas Epidémicas es decir, la evolución temporal de los casos confirmados y las defunciones. Si consultamos los diccionarios de datos, podemos ver que los casos confirmados para COVID-19 corresponden a 3 categorías de la columna clasificación final:
- CASO DE COVID-19 CONFIRMADO POR ASOCIACIÓN CLÍNICA EPIDEMIOLÓGICA
- CASO DE COVID-19 CONFIRMADO POR COMITÉ DE DICTAMINACIÓN
- CASO DE SARS-COV-2 CONFIRMADO
mientras que las defunciones corresponden a todos aquellos registros que tengan una fecha de defunción válida, es decir, en nuestros datos preprocesados, todas las fechas válidas.
4.1.1 Curva de casos confirmados
El primer paso es extraer las filas que corresponden a casos confirmados
df.CLASIFICACION_FINAL.unique()array(['NEGATIVO A SARS-COV-2',
'CASO DE COVID-19 CONFIRMADO POR COMITÉ DE DICTAMINACIÓN',
'CASO DE SARS-COV-2 CONFIRMADO', 'CASO SOSPECHOSO',
'NO REALIZADO POR LABORATORIO',
'CASO DE COVID-19 CONFIRMADO POR ASOCIACIÓN CLÍNICA EPIDEMIOLÓGICA',
'INVÁLIDO POR LABORATORIO'], dtype=object)A partir de estos valores podemos seleccionar las filas que queremos
valores_confirmados = ['CASO DE COVID-19 CONFIRMADO POR ASOCIACIÓN CLÍNICA EPIDEMIOLÓGICA',
'CASO DE COVID-19 CONFIRMADO POR COMITÉ DE DICTAMINACIÓN',
'CASO DE SARS-COV-2 CONFIRMADO']
confirmados = df.loc[df['CLASIFICACION_FINAL'].isin(valores_confirmados)]
confirmados.head()| FECHA_ACTUALIZACION | ID_REGISTRO | ORIGEN | SECTOR | ENTIDAD_UM | SEXO | ENTIDAD_NAC | ENTIDAD_RES | MUNICIPIO_RES | TIPO_PACIENTE | ... | CARDIOVASCULAR_BIN | OBESIDAD_BIN | RENAL_CRONICA_BIN | TABAQUISMO_BIN | OTRO_CASO_BIN | TOMA_MUESTRA_LAB_BIN | TOMA_MUESTRA_ANTIGENO_BIN | MIGRANTE_BIN | UCI_BIN | DEFUNCION | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | 2023-01-03 | 0741e4 | 2 | 6 | CIUDAD DE MÉXICO | 2 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | MIGUEL HIDALGO | HOSPITALIZADO | ... | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 13 | 2023-01-03 | 1c4d2e | 2 | 9 | CIUDAD DE MÉXICO | 1 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | TLALPAN | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 25 | 2023-01-03 | 0a98b4 | 2 | 12 | CIUDAD DE MÉXICO | 1 | MICHOACÁN DE OCAMPO | CIUDAD DE MÉXICO | MILPA ALTA | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 42 | 2023-01-03 | 13cf10 | 2 | 9 | CIUDAD DE MÉXICO | 1 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | BENITO JUÁREZ | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 54 | 2023-01-03 | 0fef08 | 1 | 12 | CIUDAD DE MÉXICO | 2 | CIUDAD DE MÉXICO | CIUDAD DE MÉXICO | AZCAPOTZALCO | AMBULATORIO | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
5 rows × 63 columns
Ahora tenemos una tabla con todos los casos confirmados, para hacer una curva epidémica, tenemos que agregar en una escala temporal. Lo más sencillo es primero agregar por día y a partir de ahí podemos construir agregados para cualquier intervalo que queramos.
Necesitamos decidir cuál fecha de todas las disponibles vamos a utilizar para agregar los casos. En este caso, la DGE sugiere utilizar la fecha de inicio de síntomas (FECHA_SINTOMAS) para construir la curva de casos confirmados y la de defunción (FECHA_DEF) para la curva de defunciones.
Entonces, para construir la curva de confirmados lo primero que tenemos que hacer es indexar el DataFrame por la fecha de inicio de síntomas
confirmados = confirmados.set_index('FECHA_SINTOMAS')
confirmados.indexDatetimeIndex(['2022-02-13', '2022-01-01', '2022-04-22', '2022-08-07',
'2022-01-10', '2022-01-14', '2022-12-01', '2022-05-25',
'2022-12-23', '2022-08-02',
...
'2022-06-23', '2022-08-16', '2022-08-19', '2022-08-01',
'2022-07-05', '2022-07-08', '2022-09-05', '2022-06-19',
'2022-06-20', '2022-09-23'],
dtype='datetime64[ns]', name='FECHA_SINTOMAS', length=769894, freq=None)Ya con los datos indexados es fácil construir agregados diarios, sólo tenemos que seleccionar qué columnas queremos agregar. Por lo pronto hagamos un conteo sólo de casos confirmados. Para eso sólo tenemos que agrupár el índice usando una frecuencia diaría y tomar el tamaño de los grupos (de alguna columna, realmente no importa cual).
confirmados_diarios = (confirmados
.groupby(pd.Grouper(freq='D'))[['ID_REGISTRO']] # grupos por dia y seleccionamos 'ID_REGISTRO'
.size() # Calculamos el tamaño de cada grupo
.reset_index() # Convertimos el resultado (que es una serie) en DataFrame
.rename({0:'Confirmados'}, axis=1) # Le damos nombre a la columna que obtenemos
)
confirmados_diarios| FECHA_SINTOMAS | Confirmados | |
|---|---|---|
| 0 | 2022-01-01 | 6748 |
| 1 | 2022-01-02 | 6585 |
| 2 | 2022-01-03 | 10398 |
| 3 | 2022-01-04 | 9729 |
| 4 | 2022-01-05 | 10924 |
| ... | ... | ... |
| 362 | 2022-12-29 | 715 |
| 363 | 2022-12-30 | 399 |
| 364 | 2022-12-31 | 258 |
| 365 | 2023-01-01 | 187 |
| 366 | 2023-01-02 | 80 |
367 rows × 2 columns
Hay muchas formas de visualizar estos datos, la primera y más sencilla es utilizar los métodos que provee Pandas, por ejemplo:
confirmados_diarios.set_index('FECHA_SINTOMAS').plot()<AxesSubplot: xlabel='FECHA_SINTOMAS'>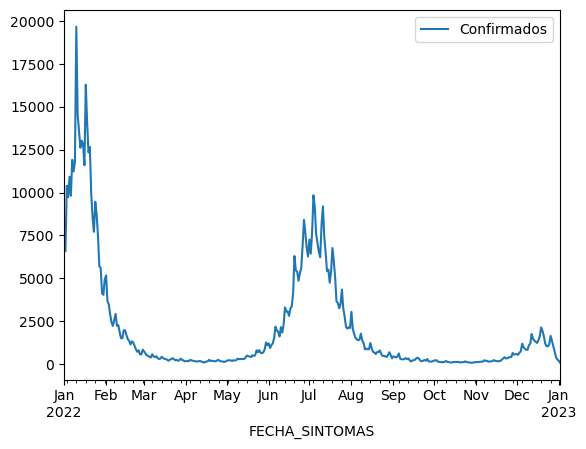
Una alternativa que nos provee herramientas interactivas para visualizar los datos y que es muy fácil de usar es Plotly. A través del módulo Plotly express podemos crear de forma muy simple gráficas que nos permitan interactuar con ellas.
fig = px.line(confirmados_diarios, x='FECHA_SINTOMAS', y="Confirmados")
fig.show()Como pueden ver, fue muy simple hacer una gráfica con herramientas para pan y zoom. Estas herramientas hacen más fácil ver que los datos de casos confirmados contienen la mezcla de dos señales: una de alta frecuancia que representa la variación diaria, con una especie de periodicidad semanal y una seññal de baja frecuencia que contiene las olas epidémicas.
La señal de alta frecuencia contiene mucho ruido que corresponde a los ciclos de actualización de la información y que realmente nos dice poco de la tendencia de los datos. Una forma sencilla de filtrar este ruido es utilizando la media móvil. Para calcular este promedio, Pandas provee la función rolling
confirmados_diarios['Media Móvil'] = (confirmados_diarios
.rolling(window=7)
.mean())
confirmados_diarios.head(10)/tmp/ipykernel_89594/2896601829.py:3: FutureWarning:
Dropping of nuisance columns in rolling operations is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the operation. Dropped columns were Index(['FECHA_SINTOMAS'], dtype='object')
| FECHA_SINTOMAS | Confirmados | Media Móvil | |
|---|---|---|---|
| 0 | 2022-01-01 | 6748 | NaN |
| 1 | 2022-01-02 | 6585 | NaN |
| 2 | 2022-01-03 | 10398 | NaN |
| 3 | 2022-01-04 | 9729 | NaN |
| 4 | 2022-01-05 | 10924 | NaN |
| 5 | 2022-01-06 | 9816 | NaN |
| 6 | 2022-01-07 | 11910 | 9444.285714 |
| 7 | 2022-01-08 | 11229 | 10084.428571 |
| 8 | 2022-01-09 | 11794 | 10828.571429 |
| 9 | 2022-01-10 | 19673 | 12153.571429 |
Y ahora la podemos graficar
fig = px.line(confirmados_diarios, x='FECHA_SINTOMAS', y='Media Móvil')
fig.show()Para graficar las dos series en la misma gráfica lo más sencillo es pasar los datos del formato ancho (en columnas) al formato largo (en filas con una columna que los distinga). Para esto vamos a usar la función melt de Pandas
confirmados_diarios = confirmados_diarios.melt(id_vars=['FECHA_SINTOMAS'], value_vars=['Confirmados', 'Media Móvil'])
confirmados_diarios| FECHA_SINTOMAS | variable | value | |
|---|---|---|---|
| 0 | 2022-01-01 | Confirmados | 6748.000000 |
| 1 | 2022-01-02 | Confirmados | 6585.000000 |
| 2 | 2022-01-03 | Confirmados | 10398.000000 |
| 3 | 2022-01-04 | Confirmados | 9729.000000 |
| 4 | 2022-01-05 | Confirmados | 10924.000000 |
| ... | ... | ... | ... |
| 729 | 2022-12-29 | Media Móvil | 1137.142857 |
| 730 | 2022-12-30 | Media Móvil | 1045.571429 |
| 731 | 2022-12-31 | Media Móvil | 934.571429 |
| 732 | 2023-01-01 | Media Móvil | 796.714286 |
| 733 | 2023-01-02 | Media Móvil | 573.714286 |
734 rows × 3 columns
Con los datos de esta forma, ahora podemos usar Plotly para graficar ambas variables utilizando como color la columna variable. El parámetro color nos permite separar dos series de datos cuando estas vienen en formato largo.
fig = px.line(confirmados_diarios, x='FECHA_SINTOMAS', y='value', color='variable')
fig.show()4.1.2 Curva de defunciones
Ya que construimos la curva de casos confirmados, la de defunciones es exáctamente igual, sólo necesitamos seleccionar al inicio del proceso los renglones que tengan una fecha de defunción válida e indexar por fecha de defunción
defunciones = confirmados.loc[confirmados['FECHA_DEF'].notnull()] # Seleccionamos los casos con fecha de defunción
defunciones = defunciones.set_index('FECHA_DEF') # indexamos por fecha de defunción
defunciones_diarios = (defunciones
.groupby(pd.Grouper(freq='D'))[['ID_REGISTRO']] # grupos por dia y seleccionamos 'ID_REGISTRO'
.size() # Calculamos el tamaño de cada grupo
.reset_index() # Convertimos el resultado (que es una serie) en DataFrame
.rename({0:'Defunciones'}, axis=1) # Le damos nombre a la columna que obtenemos
)
defunciones_diarios['Media Móvil'] = defunciones_diarios.rolling(window=7).mean() # Calculamos la media móvil
defunciones_diarios = defunciones_diarios.melt(id_vars=['FECHA_DEF'], value_vars=['Defunciones', 'Media Móvil']) # Pasamos al formato largo
fig = px.line(defunciones_diarios, x='FECHA_DEF', y='value', color='variable')
fig.show()/tmp/ipykernel_89594/3052884713.py:9: FutureWarning:
Dropping of nuisance columns in rolling operations is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the operation. Dropped columns were Index(['FECHA_DEF'], dtype='object')
4.1.3 Combinando las dos gráficas
Para entenmder la evolución de la epidemia conviene poder ver las dos gráficas al mismo tiempo y explorarlas de forma conjunta. En general este tipo de combinaciones en las que dos o más gráficas comparten por lo menos un eje (en nuestro caso el tiempo) se llaman Facetas. Plotly nos permite crear este tipo de visualizaciones de forma muy sencilla, lo que necesitamos es combinar ambos datos (casos y defunciones) en un sólo DataFrame en formato largo y asegurarnos de que cada fila pueda distinguir a qué se refiere. En nuestros datos vamos a tener cuatro series diferentes: datos crudos y media móvil para casos y definciones.
Comencemos con la serie de defunciones, lo primero que tenemos que hacer es agregar una columna con el tipo de serie, es decir, defunciones:
defunciones_diarios['Tipo'] = 'Defunciones'
defunciones_diarios| FECHA_DEF | variable | value | Tipo | |
|---|---|---|---|---|
| 0 | 2022-01-03 | Defunciones | 1.000000 | Defunciones |
| 1 | 2022-01-04 | Defunciones | 2.000000 | Defunciones |
| 2 | 2022-01-05 | Defunciones | 1.000000 | Defunciones |
| 3 | 2022-01-06 | Defunciones | 3.000000 | Defunciones |
| 4 | 2022-01-07 | Defunciones | 8.000000 | Defunciones |
| ... | ... | ... | ... | ... |
| 721 | 2022-12-27 | Media Móvil | 4.714286 | Defunciones |
| 722 | 2022-12-28 | Media Móvil | 5.285714 | Defunciones |
| 723 | 2022-12-29 | Media Móvil | 5.285714 | Defunciones |
| 724 | 2022-12-30 | Media Móvil | 5.285714 | Defunciones |
| 725 | 2022-12-31 | Media Móvil | 4.571429 | Defunciones |
726 rows × 4 columns
En la columna variable tenemos los valores Defunciones y Media Móvil, necesitamos cambiar el valor de Defunciones por algo que sea compatible con tener los casois confirmados en el mismo DataFrame, pienses que al combinar ambas series queremos tener sólo dos valores diferentes en esta columna. Cambiemos entonces el valor de Defunciones por Conteo:
defunciones_diarios.loc[defunciones_diarios['variable'] == 'Defunciones', 'variable'] = 'Conteo'
defunciones_diarios| FECHA_DEF | variable | value | Tipo | |
|---|---|---|---|---|
| 0 | 2022-01-03 | Conteo | 1.000000 | Defunciones |
| 1 | 2022-01-04 | Conteo | 2.000000 | Defunciones |
| 2 | 2022-01-05 | Conteo | 1.000000 | Defunciones |
| 3 | 2022-01-06 | Conteo | 3.000000 | Defunciones |
| 4 | 2022-01-07 | Conteo | 8.000000 | Defunciones |
| ... | ... | ... | ... | ... |
| 721 | 2022-12-27 | Media Móvil | 4.714286 | Defunciones |
| 722 | 2022-12-28 | Media Móvil | 5.285714 | Defunciones |
| 723 | 2022-12-29 | Media Móvil | 5.285714 | Defunciones |
| 724 | 2022-12-30 | Media Móvil | 5.285714 | Defunciones |
| 725 | 2022-12-31 | Media Móvil | 4.571429 | Defunciones |
726 rows × 4 columns
Ahora tenemos dos nombres diferentes para los campos con los que vamos a construir el eje de las X: FECHA_DEF y FECHA_SINTOMAS. Para poder combinar ambas series en una sola, necesitamos que esos campos tengan el mismo nombre en las dos series.
defunciones_diarios = defunciones_diarios.rename({'FECHA_DEF': 'Fecha'}, axis=1)
defunciones_diarios| Fecha | variable | value | Tipo | |
|---|---|---|---|---|
| 0 | 2022-01-03 | Conteo | 1.000000 | Defunciones |
| 1 | 2022-01-04 | Conteo | 2.000000 | Defunciones |
| 2 | 2022-01-05 | Conteo | 1.000000 | Defunciones |
| 3 | 2022-01-06 | Conteo | 3.000000 | Defunciones |
| 4 | 2022-01-07 | Conteo | 8.000000 | Defunciones |
| ... | ... | ... | ... | ... |
| 721 | 2022-12-27 | Media Móvil | 4.714286 | Defunciones |
| 722 | 2022-12-28 | Media Móvil | 5.285714 | Defunciones |
| 723 | 2022-12-29 | Media Móvil | 5.285714 | Defunciones |
| 724 | 2022-12-30 | Media Móvil | 5.285714 | Defunciones |
| 725 | 2022-12-31 | Media Móvil | 4.571429 | Defunciones |
726 rows × 4 columns
Repetimos el proceso para los datos de casos confirmados:
confirmados_diarios['Tipo'] = 'Casos Confirmados'
confirmados_diarios.loc[confirmados_diarios['variable'] == 'Confirmados', 'variable'] = 'Conteo'
confirmados_diarios = confirmados_diarios.rename({'FECHA_SINTOMAS': 'Fecha'}, axis=1)
confirmados_diarios| Fecha | variable | value | Tipo | |
|---|---|---|---|---|
| 0 | 2022-01-01 | Conteo | 6748.000000 | Casos Confirmados |
| 1 | 2022-01-02 | Conteo | 6585.000000 | Casos Confirmados |
| 2 | 2022-01-03 | Conteo | 10398.000000 | Casos Confirmados |
| 3 | 2022-01-04 | Conteo | 9729.000000 | Casos Confirmados |
| 4 | 2022-01-05 | Conteo | 10924.000000 | Casos Confirmados |
| ... | ... | ... | ... | ... |
| 729 | 2022-12-29 | Media Móvil | 1137.142857 | Casos Confirmados |
| 730 | 2022-12-30 | Media Móvil | 1045.571429 | Casos Confirmados |
| 731 | 2022-12-31 | Media Móvil | 934.571429 | Casos Confirmados |
| 732 | 2023-01-01 | Media Móvil | 796.714286 | Casos Confirmados |
| 733 | 2023-01-02 | Media Móvil | 573.714286 | Casos Confirmados |
734 rows × 4 columns
Ahora que ambas series tienen la misma forma y columnas que distinguen los cuatro casos que nos interesan, sólo resta combinar las series. En este caso, lo que queremos es pegar los datos de una abajo de la otra (el orden da igual). Para esto vamos a usar la función concat que toma una lista de DataFrames y regresa un DataFrame concatenado a lo largo del eje que queramos.
casos_defunciones = pd.concat([confirmados_diarios, defunciones_diarios], axis=0)
casos_defunciones| Fecha | variable | value | Tipo | |
|---|---|---|---|---|
| 0 | 2022-01-01 | Conteo | 6748.000000 | Casos Confirmados |
| 1 | 2022-01-02 | Conteo | 6585.000000 | Casos Confirmados |
| 2 | 2022-01-03 | Conteo | 10398.000000 | Casos Confirmados |
| 3 | 2022-01-04 | Conteo | 9729.000000 | Casos Confirmados |
| 4 | 2022-01-05 | Conteo | 10924.000000 | Casos Confirmados |
| ... | ... | ... | ... | ... |
| 721 | 2022-12-27 | Media Móvil | 4.714286 | Defunciones |
| 722 | 2022-12-28 | Media Móvil | 5.285714 | Defunciones |
| 723 | 2022-12-29 | Media Móvil | 5.285714 | Defunciones |
| 724 | 2022-12-30 | Media Móvil | 5.285714 | Defunciones |
| 725 | 2022-12-31 | Media Móvil | 4.571429 | Defunciones |
1460 rows × 4 columns
Ya con la nueva serie como la queremos, podemos hacer nuestras Facetas utlizando el parámetro facet_col que le dice a Plotly qué columna usar para distinguir las dos series. Es importante decirle que no queremos que compartan el eje \(y\) porque las escalas son muy diferentes
fig = px.line(casos_defunciones, x='Fecha', y='value', color='variable', facet_col='Tipo', facet_col_wrap=1)
fig.update_yaxes(matches=None)
fig.show()4.1.4 Hospitalizaciones
Otra gráfica muy interesante para comprender la evolucióón de la epidemia es la de hospitalizaciones. Para obtener esta gráfica primero tenemos que seleccionar los pacientes confirmados como positivos a COVID-19 y que además fueron hospitalizados.
Los casos confirmados ya los tenemos calculados en la variable confirmados, entonces falta ver cómo obtener los pacientes hospitalizados
confirmados.TIPO_PACIENTE.unique()array(['HOSPITALIZADO', 'AMBULATORIO'], dtype=object)Gracias a nuentra base aplanada es muy fácil distinguirlos, entonces sólo los tenemos que seleccionar, agregar por día y podemos hacer una gráfica como las anteriores (incluyendo la media móvil). Recordemos que confirmados está indexado por fecha de inicio de síntomas, entonces nuestra curva de hospitalización estará indexada por la misma fecha
hospitalizados = confirmados[confirmados.TIPO_PACIENTE == 'HOSPITALIZADO']
hospitalizados_diarios = (hospitalizados
.groupby(pd.Grouper(freq='D'))[['ID_REGISTRO']] # grupos por dia y seleccionamos 'ID_REGISTRO'
.size() # Calculamos el tamaño de cada grupo
.reset_index() # Convertimos el resultado (que es una serie) en DataFrame
.rename({0:'Hospitalizaciones'}, axis=1) # Le damos nombre a la columna que obtenemos
)
hospitalizados_diarios['Media Móvil'] = hospitalizados_diarios.rolling(window=7).mean()
hospitalizados_diarios = hospitalizados_diarios.melt(id_vars=['FECHA_SINTOMAS'], value_vars=['Hospitalizaciones', 'Media Móvil'])
fig = px.line(hospitalizados_diarios, x='FECHA_SINTOMAS', y='value', color='variable')
fig.show()/tmp/ipykernel_89594/1651814779.py:8: FutureWarning:
Dropping of nuisance columns in rolling operations is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the operation. Dropped columns were Index(['FECHA_SINTOMAS'], dtype='object')
Y, una vez más, para comparar vamos a poner las tres gráficas (casos confirmados, defunciones y hospitalizacones) en un Facet
hospitalizados_diarios['Tipo'] = 'Hospitalizaciones'
hospitalizados_diarios.loc[hospitalizados_diarios['variable'] == 'Hospitalizaciones', 'variable'] = 'Conteo'
hospitalizados_diarios = hospitalizados_diarios.rename({'FECHA_SINTOMAS': 'Fecha'}, axis=1)
hospitalizados_diarios| Fecha | variable | value | Tipo | |
|---|---|---|---|---|
| 0 | 2022-01-01 | Conteo | 117.000000 | Hospitalizaciones |
| 1 | 2022-01-02 | Conteo | 91.000000 | Hospitalizaciones |
| 2 | 2022-01-03 | Conteo | 124.000000 | Hospitalizaciones |
| 3 | 2022-01-04 | Conteo | 120.000000 | Hospitalizaciones |
| 4 | 2022-01-05 | Conteo | 144.000000 | Hospitalizaciones |
| ... | ... | ... | ... | ... |
| 729 | 2022-12-29 | Media Móvil | 35.285714 | Hospitalizaciones |
| 730 | 2022-12-30 | Media Móvil | 33.857143 | Hospitalizaciones |
| 731 | 2022-12-31 | Media Móvil | 31.285714 | Hospitalizaciones |
| 732 | 2023-01-01 | Media Móvil | 27.857143 | Hospitalizaciones |
| 733 | 2023-01-02 | Media Móvil | 21.571429 | Hospitalizaciones |
734 rows × 4 columns
Combinamos con la serie de casos y defunciones
casos_defunciones_hospitalizaciones = pd.concat([hospitalizados_diarios, casos_defunciones], axis=0)
casos_defunciones_hospitalizaciones| Fecha | variable | value | Tipo | |
|---|---|---|---|---|
| 0 | 2022-01-01 | Conteo | 117.000000 | Hospitalizaciones |
| 1 | 2022-01-02 | Conteo | 91.000000 | Hospitalizaciones |
| 2 | 2022-01-03 | Conteo | 124.000000 | Hospitalizaciones |
| 3 | 2022-01-04 | Conteo | 120.000000 | Hospitalizaciones |
| 4 | 2022-01-05 | Conteo | 144.000000 | Hospitalizaciones |
| ... | ... | ... | ... | ... |
| 721 | 2022-12-27 | Media Móvil | 4.714286 | Defunciones |
| 722 | 2022-12-28 | Media Móvil | 5.285714 | Defunciones |
| 723 | 2022-12-29 | Media Móvil | 5.285714 | Defunciones |
| 724 | 2022-12-30 | Media Móvil | 5.285714 | Defunciones |
| 725 | 2022-12-31 | Media Móvil | 4.571429 | Defunciones |
2194 rows × 4 columns
Graficamos las tres series
fig = px.line(casos_defunciones_hospitalizaciones, x='Fecha', y='value', color='variable', facet_col='Tipo', facet_col_wrap=1)
fig.update_yaxes(matches=None)
fig.show()